Berenice Chavez Rojas graduated from SFSU in 2021 with a major in biology and a minor in computing applications. She is moving to Boston to work in a lab at Harvard’s Medical School.
Pleuni: Hi Berenice, congratulations on graduating this semester!
I know that you are starting a job at Harvard soon. Would you mind telling me what you’ll be doing there and how you found that job? Did your coding skills help you land this job?
Berenice: I’ll be working as a research assistant in a wet lab. The model organism is C. elegans and the project will focus on apical-basal polarity in neurons and glia. I found this job on Twitter! Having a science Twitter is a great way to find research and job opportunities as well as learn new science from other scientists. While I won’t be using my computational skills as part of this job, the research experience I have been able to obtain with my coding skills did help me.
“coding always seemed intimidating and unattainable”
Pleuni: When did you start to learn coding?
Berenice: I started coding after I was accepted to the Big Data Summer Program two years ago [Note from Pleuni: this is now the PINC Summer Program]. This was also my first exposure to research and I’m grateful I was given this opportunity. This opportunity really changed my experience here at SFSU and it gave me many new opportunities that I don’t think I would have gotten had I not started coding. Following the Big Data Summer Program I started working in Dr. Rori Rohlfs’ computational biology lab. I also received a fellowship [https://seo.sfsu.edu/] which allowed me to stop working my retail job, this gave me more time to focus on school and research.
Pleuni: Did you always want to learn coding?
Berenice: Not at all, coding always seemed intimidating and unattainable. After my first exposure to coding, I still thought it was intimidating and I was slightly hesitant in taking CS classes. Once I started taking classes and the more I practiced everything began to make more sense. I also realized that Google and StackOverflow were great resources that I could access at any time. To this day, I still struggle and sometimes feel like I can’t make any progress on my code, but I remind myself that I’ve struggled many times before and I was able to persevere all those times. It just takes time!

“At the end of this project, I was able to see how much I had learned and accomplished”
Pleuni: You did the entire PINC program – which part did you like most? Which part was frustrating?
Berenice: My favorite part of the PINC program was working on a capstone project of our choice. At the end of this project, I was able to see how much I had learned and accomplished as part of the PINC program and it was a great, rewarding feeling. As with any project, our team goals changed as we made progress and as we faced new obstacles in our code. Despite taking many redirections, we made great progress and learned so much about coding, working in teams, time management, and writing scientific proposals/reports.
Link to a short video Berenice made about her capstone project: https://www.powtoon.com/c/eKaZB3kkxE5/0/m
Pleuni: Sometimes it looks like coding is something for only some kinds of people. There are a lot of stereotypes associated with coding. How do you feel about that?
Berenice: I think computer science is seen as a male-dominated field and this makes it a lot more intimidating and may even push people away. The PINC program does a great job of creating a welcoming and accepting environment for everyone. As a minority myself, this type of environment made me feel safe and I felt like I actually belonged to a community. Programs like PINC that strive to get more students into coding are a great way to encourage students that might be nervous about taking CS classes due to stereotypes associated with such classes.
“talking to classmates […] was really helpful”
Pleuni: Do you have any tips for students who are just starting out?
Berenice: You can do it! It is challenging to learn how to code and at times you will want to give up but you can absolutely do it. The PINC instructors and your classmates are always willing to help you. I found that talking to classmates and making a Slack channel where we could all communicate was really helpful. We would post any questions we had and anyone could help out and often times more than a few people had the same question. Since this past year was online, we would meet over Zoom if we were having trouble with homework and go over code together. Online resources such as W3Schools, YouTube tutorials and GeeksforGeeks helped me so much. Lastly, don’t bring yourself down when you’re struggling. You’ve come so far; you can and will accomplish many great things!
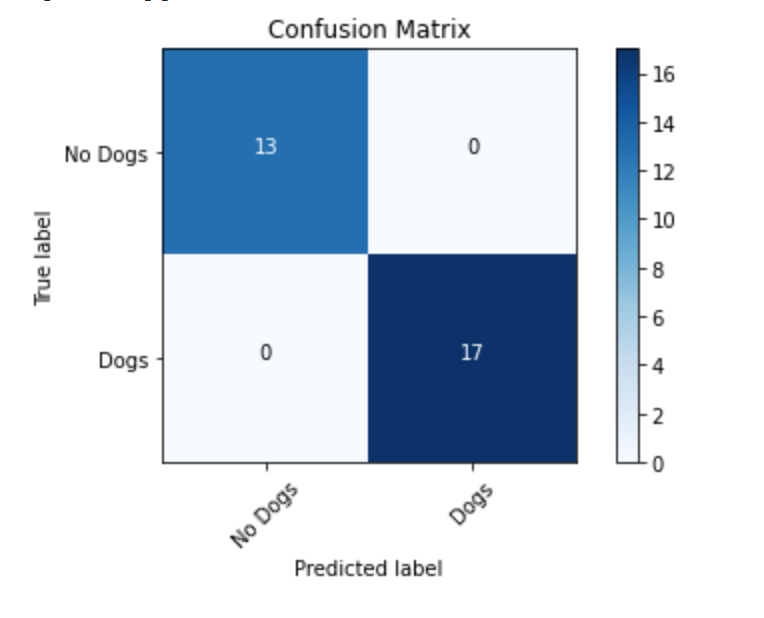
Pleuni: What’s your dog’s name and will it come with you to Boston?
Berenice: His name is Bowie and he’ll be staying with my family here in California.
Pleuni: Final question. Python or R?
Berenice: I like Python, mostly because it’s the one I use the most.
Pleuni: Thank you, Berenice! Please stay in touch!








 .
.